
変数
変数とは様々なデータ型の値を入れる入れ物です。変数を使用するときはデータ型を宣言して値を入れる必要があります。変数にデータを入れることを代入と呼び、「=」を使用します。宣言と代入を同時に行うことを初期化と呼びます。
まずは、数値型の整数型をご紹介します。その名の通り整数のみしか代入できません。例えばintは8bitのデータを代入できますが、それは「2の8乗の範囲のデータを代入できる」ということです。intの場合はマイナスも代入できるのでその半分の範囲のプラスとマイナスのデータを代入することができます。
「unsigned」とは符号がないという意味で、unsignedを付けた場合はマイナスのデータは持てませんがunsignedがない場合と比較してプラスを2倍の範囲まで代入することができます。
| データ型 | bit | 範囲 |
| int | 8 | -128~127 |
| unsigned int | 8 | 0~255 |
| long | 32 | ±約20億 |
| unsigned long | 32 | 0~約40億 |
| short | 16 | ±約3万 |
| unsigned short | 16 | 0~約6万 |
| char | 8 | 128~127 |
| unsigned char | 8 | 0~255 |
実際に整数型の変数を宣言して代入してみます。
//以下の2つは同じこと
int a; //整数型のaを宣言
a = 2; //aに2を代入
int a = 2; //aを初期化次に実数型です。こちらは小数も扱うことができる変数になります。
| データ型 | bit | 範囲 |
| float | 32 | ±約3.4×10の38乗 |
| double | 64 | ±約1.7×10の308乗 |
float a = 1.2;次にchar型です。アスキーコードといってコンピュータは文字に数値を割り当てて識別しています。char型は半角英数の1文字のみしか入れることができませんので注意が必要です。宣言の仕方をご紹介します。char型の文字は「’」シングルクォーテーションでくくります。
//以下の2つは同じこと
char c = 'C';
char c = 67;
//'C'と67は同じ次に文字列型です。こちらは文字型の配列を用意して宣言します。文字列型は「”」ダブルクォーテーションでくくります。PythonやJavaなどと比較してC言語で文字列を扱う場合に異なる点が2点あります。
1つは使用する際に格納する文字数+NULL(1文字分)を足した要素数の箱を宣言します。NULLというのはここで文字列の最後と表現するために付けられます。ただ、宣言時にこの箱の要素数は省略することもできます。
「a」「p」「p」「l」「e」「NULL」で6文字分の箱が必要になります。
//以下の2つは同じこと
char a[6] = "apple";
char a[] = "apple";
//[]を空欄にすると自動で箱を用意します もう1点はやっかいなのですが、初期化の時しか「=」で変数に文字列を代入することができません。初期化した後に文字列を代入する場合は以下のように「strcpy_s」を使用します。※「strcpy(sなし)」はトラブル防止のためビルドでエラーが発生するようになったため、この入門では使用を避けます。
//以下の2つは同じこと
//初期化時に代入
char str[6] = "apple"
//初期化後に代入
char str[6];
strcpy_s(str, 6, "apple");
//strcpy_s(変数名, 要素数, 文字列)最後にキャスト演算子についてご紹介します。キャスト演算子を使用するとすでに特定のデータ型で宣言したものを別のデータ型に変換して処理をさせることができます。
int a = 5; //整数型
//intのまま2で割ると小数点以下は
//切り捨てになる
a / 2;
//結果は2
//floatに変換
(float)a / 2;
//結果は2.5
//表示にはprintfという関数を
//使用しますが次回ご説明します
//右が切れたら左にスワイプしてください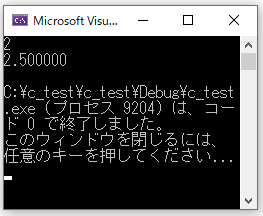
他の言語をすでに習得されている方はかなり面倒に感じるかと思いますが次回さらに面倒になります。まずはここまで理解をお願いします。
printf
printfで変数を表示してみます。以前の回でprintfは使ったじゃないかと思われる方もおられるかもしれませんが、今回はC言語が他の言語と比較してかなり面倒な部分が見えてきます。
まずは前回ご紹介した「Hello, World」で復習します。次のように記述する必要がありました。
prntf("Hello, World");次に整数型(int)の変数を表示する場合はこのようになります。
int a = 5;
printf("%d\n", a); //\nは改行
//実行結果
//5いきなり謎の「%d」出てきました。%dというのはどのようなフォーマットでデータを表示するかを指定しています。この %d は英語で「format specifier」と呼びます。なぜ英語表記を最初にお伝えしたかというと日本語での呼び方が明確に決まっていないためです。「フォーマット指定子」「変換指定子」「書式指定子」など呼ばれるのですが、このC言語入門ではフォーマット指定子で統一したいと思います。フォーマット指定子には次の種類があります。
| フォーマット演算子 | 意味 |
| %d | 整数(10進数) |
| %f | 実数(小数点有効な10進数) |
| %c | 文字(’ ‘で囲んだ半角1文字) |
| %s | 文字列(” “で囲む) |
実際にフォーマット指定子を使用して整数型、実数型、文字型、文字列型の変数をprintfで表示してみます。失敗した場合も一緒にご紹介しますが、注意して見てもらいたいのはchar型の文字型です。
#include <stdio.h>
main()
{
int a = 5;
float b = 1.2;
char c = 'A';
char d[6] = "apple";
//int(整数型)を%dで表示
printf("a = %d\n", a);
//float(実数型)を%fで表示
printf("b = %f\n", b);
//char(文字型)を%cで表示
printf("c = %c\n", c);
//char(文字型)を%dで表示
printf("c = %d\n", c);
//char(文字列)を%sで表示
printf("d = %s\n", d);
printf("失敗");
//フォーマットの指定を失敗
//int(整数型)を%fで表示
printf("a = %f\n", a);
//float(実数型)を%dで表示
printf("b = %d\n", b);
}
//右が切れたら左にスワイプしてください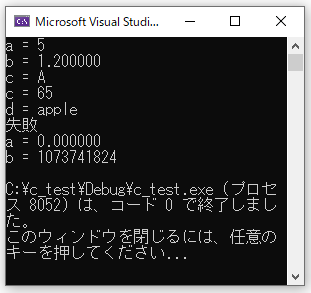
intを 実数(%f) 、floatを整数(%d)で表示しようとすると分かりやすく失敗しました。しかし、charを整数や文字で表示するのは2パターンとも正しい使い方になります。charを文字(%c)で表示すると変数に代入した「A」、整数(%d)で表示しようとするとAを数字(アスキーコード)で表した「65」が表示されました。このようにcharを使用する時にはどのフォーマット指定子の使い方が重要になります。
最後にエスケープシーケンスについてご説明します。printfの中で使用されている「\n」のことです。このサイトや多くのエディタでは「\n」と表示されてしまいますが、「¥n」が正式な表記になり特殊な命令を行う時に使用されます。まずは「\n = ¥n(改行)」だけで十分かと思います。ちなみに僕は「¥n」以外を今まで使用したことはありません。
| エスケープシーケンス | 機能 |
| ¥0 | NULL文字 |
| ¥b | バックスペース |
| ¥t | タブ |
| ¥n | 改行(LF) |
| ¥r | 復帰(CR) |
他のプログラミング言語を習得されている方からすると、面倒なことに驚くかと思いますが、フォーマット指定子は非常に重要なのでしっかりと理解をお願いします。
演算子
算数では「足し算と引き算」よりも「かけ算と割り算」を優先し、さらに「()」の中が最優先でしたね。例えば次の計算ですが、
(1+2) × 3 + 2 = 11 となります。C言語で四則演算の記号は次で表現します。(演算子の部分は見やすいように一部全角を使用していますが実際は半角で入力してください)
| 演算子 | 意味 |
| + | 足し算 |
| - | 引き算 |
| * | かけ算 |
| / | 割り算の商 |
| % | 割り算のあまり |
a = 1 + 1; //a = 2
b = 3 - 1; //b = 2
c = 3 * 2; //c = 6
d = 7 / 2; //d = 3
e = 7 % 2; //e = 1前回までに次のような式が出てきました。このように「int a」とすることを変数の宣言と呼び、「a = 2」と値を入れることを代入と呼びました。それを同時に行うことを初期化と呼びました。
int a; //変数の宣言
a = 2; //代入
int a = 2; //初期化これは「aは2」というのは理解しやすいと思います。それでは次はどうでしょうか?
int a = 2;
a = a + 1;数学ではありえない方程式ですね。右辺と左辺のバランスがとれていません。これはプログラミングでは「aに1を追加する」ことを表しています。数学の「=」とは意味が異なりますので注意してください。「aに1を足す」「aから1を引く」という表現には次のようにインクリメントとデクリメントという表現で行う場合もあります。Javaでも使われますが「Pythonではこの表現は分かりづらいので対応しない」ということになっているようですので注意が必要です。
a = a + 1;
a++; //インクリメント
a = a - 1;
a--; //デクリメント比較演算子と論理演算子
比較演算子と論理演算子を使用すると条件をもうけることができ、満たしているか、満たしていないかで処理を変化させることができます。まずは比較演算子を表にまとめます。
| 比較演算子 | 意味 |
| A > B | AはBより大きい |
| A >= B | AはB以上 |
| A < B | AはBより小さい |
| A <= B | AはB以下 |
| A == B | AとBは一致する |
| A != B | AとBは一致しない |
論理演算子を表にまとめます。
| 論理演算子 | 意味 |
| A && B | AとBの両方が成立する |
| A || B | AとBの片方が少なくとも成立する |
| !A | Aは成立しない |
比較演算子と論理演算子を使用して条件が成立する場合をtrueと呼び「1」をいう値を持ちます。対して条件が成立しない場合をfalseと呼び「0」を持ちます。テストを行ってみます。
#include<stdio.h>
main()
{
int a = 1;
int b = 2;
//比較演算子のテスト
printf("a = %d, b = %d\n", a, b);
printf("a < b\n");
printf("%d\n", a < b);
printf("a > b\n");
printf("%d\n\n", a > b);
//論理演算子のテスト
printf("a = %d, b = %d\n", a, b);
printf("a = 1 and b = 1\n");
printf("%d\n", a == 1 && b == 1);
printf("a = 1 or b = 1\n");
printf("%d\n", a == 1 || b == 1);
}
//右が切れたら左にスワイプしてください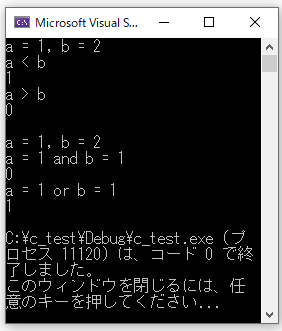
次に参考までに三項演算子というやり方で条件をもうけて代入する値を変える方法をご紹介します。ただ、この三項演算子は分かりづらいため別の回でご紹介するif文を使用することをおすすめします。
#include<stdio.h>
main()
{
int a = 1;
int b = 2;
int result;
//三項演算子のテスト
//aがb以下ならa+b, それ以外なら0を表示
result= (a <= b) ? (a + b) : 0;
printf("result = %d\n", result);
}
//右が切れたら左にスワイプしてください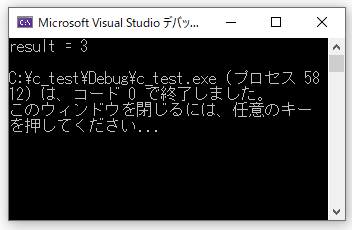
このように三項演算子は分かりづらいので使用を避けた方が無難です。このような方法もC言語にはあるとだけご紹介させて頂きました。
if文・else if文
if文は様々なプログラミング言語で使用されている構文で条件をもうけて処理を分岐するために使用されます。
if (条件)
{
処理A;
}
else
{
処理B;
}実際の使用例をご紹介します。
#include <stdio.h>
main()
{
int ht = 165;
if (ht > 170)
{
printf("Lサイズ\n");
}
else
{
printf("Mサイズ\n");
}
}
//右が切れたら左にスワイプしてください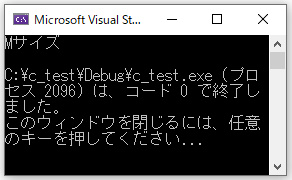
次はもう少し複雑な分岐に挑戦したいと思います。else if文を使用するとif文の分岐を増やすことができます。
if (条件)
{
処理A;
}
else if (条件)
{
処理B;
}
else
{
処理C;
}実際の使用例をご紹介します。
#include <stdio.h>
main()
{
int ht = 175;
if (ht > 180)
{
printf("LLサイズ\n");
}
else if (ht > 170)
{
printf("Lサイズ\n");
}
else
{
printf("Mサイズ\n");
}
}
//右が切れたら左にスワイプしてください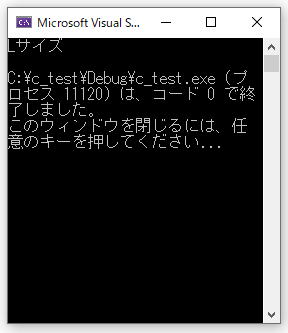
if文の中にもif文を入れることができます。このような状態をネストと呼びます。次のソースコードは先ほどのものと全く同じ結果になりますがネストにしています。
#include <stdio.h>
main()
{
int ht = 175;
if (ht > 170)
{
if (ht > 180)
{
printf("LLサイズ\n");
}
else
{
printf("Lサイズ\n");
}
}
else
{
printf("Mサイズ\n");
}
}
//右が切れたら左にスワイプしてくださいif文の中にif文、さらにif文と続くことを「ネストが深い」と呼び、分かりにくいプログラムになってしまうため注意してください。
for文
for文を使用すると同じ処理(繰り返し)を行うときに便利です。
for (カウンタ初期値; 条件; カウントアップ)
{
処理A;
}
//右が切れたら左にスワイプしてください 実際の使用例をご紹介します。
#include <stdio.h>
main()
{
int i;
for (i = 0; i < 5; i++)
{
printf("%d\n", i);
}
}
//右が切れたら左にスワイプしてください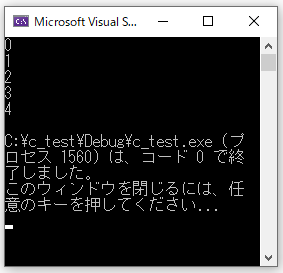
今回の例のようにカウンタには「i」が良く使用されます。その理由は暗黙のうちにプログラミングではカウンタに「i」が使用されるからです。諸説はありますが、慣れているプログラマーであれば「i」を見ると「カウンタのことだな」と理解してもらえますのでこだわりがなければ「i」を使用することをお勧めします。
while文
while文はfor文と同じく繰り返し処理を行う時に使用します。
while(条件)
{
処理;
}実際の使用例をご紹介します。
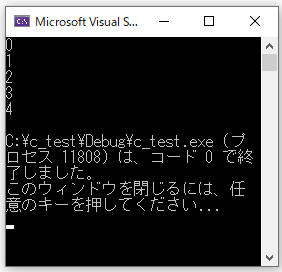
#include <stdio.h>
main()
{
int i = 0;
while (i < 5)
{
printf("%d\n", i);
i++;
}
}
do while文という構文も有名ですのでご紹介します。
do {
処理;
} while(条件)#include <stdio.h>
main()
{
int i = 0;
do {
printf("%d\n", i);
i++;
} while (i < 5);
}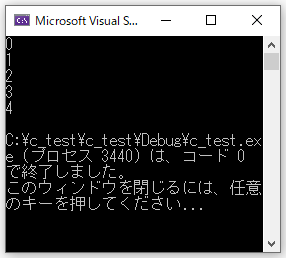
do whileは条件の前に処理があるため、1度は無条件で処理を実行するという特徴があります。
最後にwhile文をして無限ループを行う方法をご紹介します。while文の条件を「1」に固定することで永遠に処理を繰り返すことができます。
#include <stdio.h>
main()
{
while (true)
{
printf("無限ループ\n");
}
}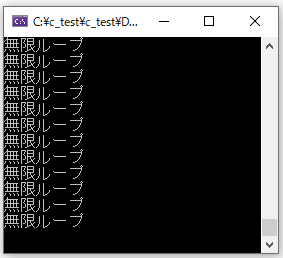
無限ループは様々なところで活用されます。止まりませんので右上の「×」を押して停止してください。
break文とcontinue文
break文を使用すると以前ご紹介したfor文やwhile文を中断することができます。
#include <stdio.h>
main()
{
int i = 0;
while (i < 6)
{
printf("%d\n", i);
if (i == 3)
{
break; //中断
}
i++;
}
}
//右が切れたら左にスワイプしてください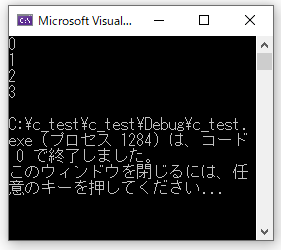
while文の条件は「i < 6」でしたが、break文によって中断がされました。
次はcontinue文です。こちらを使用するとその条件だけをスキップすることができます。
#include <stdio.h>
main()
{
int i = 0;
while (i < 6)
{
if (i == 3)
{
continue; //スキップ
}
printf("%d\n", i);
i++;
}
}
//右が切れたら左にスワイプしてください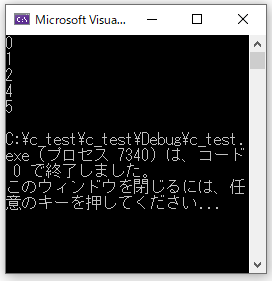
ループを中断するbreak文と異なりcontinue文はあくまでスキップしてその名の通り復帰する処理になります。
switch文
switch文はif文のように条件をもうけて分岐させる構文です。
switch(変数)
{
case 値1:
処理1;
break;
case 値2:
処理2;
break;
・
・
・
default: //それ以外
処理3;
}実際の例をご紹介します。
#include <stdio.h>
main()
{
int a = 3;
switch(a)
{
case 0:
printf("%d\n", a);
break;
case 1:
printf("%d\n", a);
break;
default:
printf("それ以外\n", a);
}
}
//右が切れたら左にスワイプしてください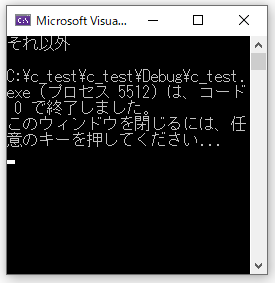
if文よりもシンプルに表記できる反面、条件は変数のみで比較演算子や論理演算子を使用することはできませんので注意してください。
配列
配列とは同じデータ型の複数の変数をまとめて管理する方法です。まずは数値型のデータを配列にしています。
//配列の初期化
//インデックス 0, 1, 2, 3
int a[3] = {0, 1, 2, 3};
//インデックスを省略することも可
int a[] = {0, 1, 2, 3};
//以下のように宣言もできる
int a[3];
a[0] = 0;
a[1] = 1;
a[2] = 2;
a[3] = 3;
//右が切れたら左にスワイプしてください実際に使用してみます。
#include <stdio.h>
main()
{
int i;
int a[] = {0, 1, 2, 3};
for (i = 0; i < 4; i++)
{
printf("%d\n", a[i]);
}
}
//右が切れたら左にスワイプしてください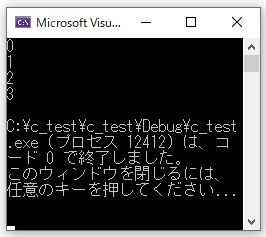
次は文字列型を配列にしてみます。
//配列の初期化
char s[] = "ABC";
//数値型のようにこうも書けます
//インデックス 0 1 2 3
char s[3] = {'A', 'B', 'C', '\0'};
//以下のように宣言もできる
int a[3];
a[0] = 'A';
a[1] = 'B';
a[2] = 'C';
a[3] = '\0'; //最後に必ず「¥0」
//右が切れたら左にスワイプしてください実際に使用しています。
#include <stdio.h>
main()
{
int i = 0;
char s[] = "ABC";
for (i = 0; i < 4; i++)
{
printf("%c\n", s[i]); //%c
}
s[1] = 'D'; //値を変更
printf("%s", s); //%s
//右が切れたら左にスワイプしてください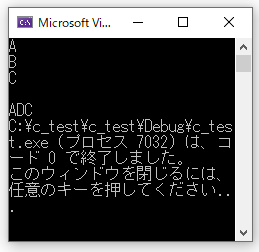
s [ i ] という文字(1文字)を呼び出すときには%c、sという文字列を呼び出すときには%sを使用しますので注意してください。
アドレス
変数の値はコンピュータのメモリに保管されてます。メモリには1byteごとにアドレスという番号が割り振られています。まずはテストをしてみます。
#include <stdio.h>
main()
{
int a = 2;
char c = 'A';
printf("a_add %x\n", &a;);
printf("c_add %x\n", &c;);
}
//右が切れたら左にスワイプしてください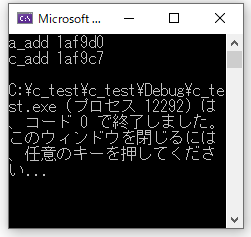
このソースコードで「&a」はaのアドレスを表しています。「%x」は数値を16進数で表示するフォーマット演算子です。まずはここまでご理解をお願いします。
ポインタ
C言語の難関のポインタをご紹介します。
| 住所 | 名義 |
| 1丁目2番地 | 太郎 |
①太郎の住所は「1丁目2番地」
②1丁目2番地の名義は「太郎」
この2つの文章を元にポインタを説明します。まずは①ですが太郎を変数aとすると
①a(太郎)のアドレス(住所)は&a(1丁目2番地)
となります。これは前回ご説明しましたね。次に②ですが、住所をpとするとC言語ではこのように表現します。
②p(1丁目2番地)の値(名義)は*p(太郎)
このpのようにアドレス(住所)を表す変数をポインタと呼びます。
ポインタのイメージが難しい方もおられるかと思いますので表でご説明します。
| アドレス (住所) | 値 (名義) |
| 1丁目2番地 | 太郎 |
| &a | a |
| p | *p |
この表のように「a = *p」「p = &a」が成り立ちます。
実際にテストしてみます。
#include <stdio.h>
main()
{
char a;
char *p; //ポインタ変数は前に*
a = 'A';
p = &a;
//変数aを基準
printf("%x\n", &a;);
printf("%c\n", a);
//ポインタ変数pを基準
printf("%x\n", p);
printf("%c\n", *p);
}
//右が切れたら左にスワイプしてください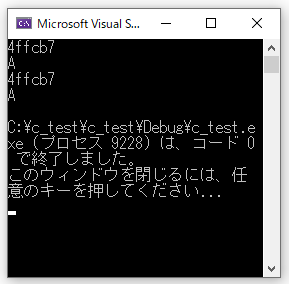
ポインタはC言語の最初の難関ですが、可能な限り簡単にご説明できるようにしてみました。アドレスという概念が理解できるまでポインタは理解が難しいですが、しっかりとご理解をお願いします。
関数
関数を今回ご説明します。「y = 2x」という数学の関数があります。xのように関数に与える値を「引数」と呼び、yのようにx(引数)によって変化して返ってくる値を「戻り値」と呼びます。関数の定義の仕方は次のように行います。
戻り値の型 関数名(第1引数,第2引数…)
{
処理;
return 戻り値;
}
//関数の定義(例)
int max(int a, int b)
{
if (a >= b)
{
return a;
}
else
{
return b;
}
}
//戻り値がない関数
void print(int a)
{
printf("%d", a);
return; //省略しても良い
}
//右が切れたら左にスワイプしてください実際に関数を呼び出して使用してみます。
#include <stdio.h>
//大きい方を表示する
int max(int a, int b)
{
if (a >= b)
{
return a;
}
else
{
return b;
}
}
main()
{
int c = 5;
int d = 7;
int e;
e = max(c,d);
printf("%d\n", e);
}
//右が切れたら左にスワイプしてください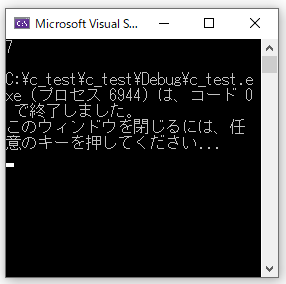
いろいろな関数を自作して関数の取り扱いに慣れてください。
スコープ
スコープとは変数の有効範囲のことです。関数内で宣言した変数は「ローカル変数」と呼び、宣言した関数の中でしか使用できません。それに対して関数の外で宣言した変数を「グローバル変数」と呼び、全ての関数で使用できます。
#include <stdio.h>
//関数の外で宣言
int a = 1; //グローバル変数
int b = 2; //グローバル変数
void func1()
{
//func1関数の中で宣言
int c = 3; //ローカル変数
処理;
}
main()
{
//aとbは使用できますが
//cは使用できません。
処理;
}
//aとbのスコープは全範囲
//cのスコープはfunc1関数のみ
//右が切れたら左にスワイプしてください全範囲で使用する変数を特定の関数内で宣言しないように注意してください。
関数のプロトタイプ
前回、関数を使用するときにはまず関数の定義を行った後にmain関数で呼び出して使用していました。しかし、大規模なプログラムで関数が大量にある場合、main関数の前にどっさりと関数を記述すると作業がやりづらかったり、見にくいソースコードになります。
#include <stdio.h>
大量の関数を定義
・
・
・
・
・
・
//例えば2000行以上
//ふう・・・やっとmain関数
main()
{
処理;
}
このように関数がたくさんある場合にすっきりと記述するための方法が「関数のプロトタイプ宣言」です。方法をご紹介します。
#include <stdio.h>
//1つの関数につき1行だけでOK
戻り値の型 関数名(第1引数…);
main()
{
処理;
}
//main関数の後ろに関数を定義
戻り値の型 関数名(第1引数…)
{
処理;
return 戻り値;
}
//右が切れたら左にスワイプしてください⑰で作成した関数をプロトタイプ宣言してみます。
#include <stdio.h>
//1行で済みます
int max(int a, int b);
main()
{
int c = 5;
int d = 7;
int e;
e = max(c,d);
printf("%d\n", e);
}
//mainの後ろで関数を宣言
int max(int a, int b);
{
if (a >= b)
{
return a;
}
else
{
return b;
}
}
//右が切れたら左にスワイプしてください結果は全く同じです。main関数の前にどっさりと記述があるとスクロールする手間が増えたり作業しづらいので大規模なプログラムを作成するときにはプロトタイプ宣言を行うことをお勧めします。
構造体
構造体を使用すると複数のデータ型の変数をまとめて管理することができて便利です。スポーツジムの入会申込書を例にご説明します。この入会申込書は身長、体重の項目がありますが、これらをメンバと呼び、どういうデータ型の変数をまとめるかを宣言することを「構造体テンプレートの宣言」と呼びます。
| 入会申込書 | ||
| 身長 | ht | |
| 体重 | wt |
太郎さんが入会申込書に記入をしました。このようにテンプレートに具体的な値を入力することを「構造体変数の宣言」と呼びます。
| 入会申込書 | ||
| 身長 | ht | 170 |
| 体重 | wt | 60 |
C言語で実際に構造体テンプレートの宣言と構造体変数の宣言を行う場合は以下のようにします。このC言語入門は完全な初心者の方を想定していますので、まず構造体の中は数値型を2つだけ入れてご説明し、徐々に増やしたいと考えております。
//構造体テンプレートの宣言
struct data {
int ht;
int wt;
};
//構造体変数の宣言のみ
struct data taro;
//構造体変数の宣言と初期化を同時
struct data taro = {170, 60};
//縦に書いても良い
struct data taro = {170,
60
};
//右が切れたら左にスワイプしてください構造体のメンバへのアクセスは次のように行います。
構造体変数名.メンバ名
//太郎の体重を書き換える
taro.wt = 55;実際に使用してみます。
#include <stdio.h>
//構造体テンプレートの宣言
//まずは数値型を2個だけで慣れる
struct man {
int ht;
int wt;
};
main()
{
//構造体変数の宣言と初期化
struct man taro = {170,60};
taro.wt = 55; //wtを変更
printf("ht:%d\n", taro.ht);
printf("wt:%d\n", taro.wt);
}
//右が切れたら左にスワイプしてください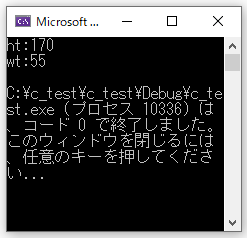
すでに他の言語を習得されている方は構造体はクラスをインスタンス化してフィールドにアクセスするのと一緒と思われた方もおられるかと思います。たしかに非常に似ているのですがC言語は構造体の中にメソッドを持てないという特徴がありますのでご注意ください。
構造体のポインタ
構造体をポインタで参照する方法を今回ご紹介します。構造体も普通の変数と同じように「*」を付けてポインタ変数の宣言を行います。
//構造体テンプレートの宣言
struct data{
int ht;
int wt;
};
//構造体のポインタ変数を宣言
staruct data *p;数値型が1個入っている場合、ポインタ変数pのアドレスにあるデータを参照するときは*pとする必要がありましたが構造体の場合は「アロー演算子」を使用します。
ポインタ名 -> メンバー
p -> wt
//ポインタ変数pのメンバーである
//wtの値を参照する実際に使用して動作を見てみます。
#include <stdio.h>
//構造体テンプレートの宣言
struct man{
int ht;
int wt;
};
main()
{
struct man taro = {170,60};
struct man *p;
p = &taro;
p -> wt = 55; //wtを変更
printf("%d\n", p -> ht);
printf("%d\n", p -> wt);
}
//右が切れたら左にスワイプしてください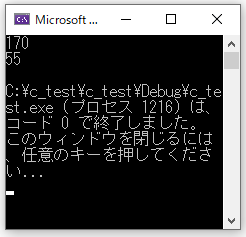
「*」かアロー演算子を使用するかの違いはありますが、構造体のポインタも通常の変数の場合と考え方は同じです。ポインタの概念を理解するとC言語の理解が一気に深まりますので、ちょっと自信がない方はゆっくりと理解してもらえればと思います。
構造体に文字列を入れる
今回は構造体のメンバーに文字列を使用してみます。
//構造体テンプレートの宣言
struct man {
char name[10];
int age;
};
//構造体変数の宣言のみ
struct man taro;
//構造体変数の宣言と初期化を同時
struct man taro = {"taro",20};
//縦に書いても良い
struct man taro = {"taro",
20
};実際にテストしてみます。
#include <stdio.h>
struct man {
char name[10];
int age;
};
main()
{
//構造体変数の宣言と初期化
struct man taro = {"taro",20};
//taro.name ="aki"; これではエラー
strcpy_s(taro.name, 10,"aki");
printf("%s\n", taro.name);
printf("%d\n", taro.age);
}
//右が切れたら左にスワイプしてください
以前、ご説明しましたがC言語の場合、文字列は1度代入をすると変更できず、strcpy_sを使用する必要があるため手間がかかります。
しかし、実は次のように構造体の中の文字列をポインタで宣言することで使い勝手が良くなります。実行結果は先ほどと同じです。ここから先はまだ理解されなくて大丈夫です。参考程度にさらっと確認してもらえればと思います。
#include <stdio.h>
struct man {
char *name; //ポインタで宣言
int age;
};
main()
{
//構造体変数の宣言と初期化
struct man taro = {"taro",20};
taro.name = "aki"; //代入でOK
printf("%s\n", taro.name);
printf("%d\n", taro.age);
}
//右が切れたら左にスワイプしてくださいさらに構造体の中の文字列をポインタで宣言するメリットがあります。最初のchar name[10]だとNULLがあるので9文字までしか変数に入れることができません。しかも、構造体の中のcharはchar name[]のように要素数を省略することができません。しかし、ポインタで宣言すると新たに代入する文字列の長さが事実上制限されなくなります。そのため、どのくらいの長さの文字列が入るか予想しづらい場合は安心です。
#include <stdio.h>
struct man {
char *name; //ポインタで宣言
int age;
};
main()
{
//構造体変数の宣言と初期化
struct man taro = { "taro",20 };
taro.name = "taroooooooooooooooooooooooo"; //代入でOK
printf("%s\n", taro.name);
printf("%d\n", taro.age);
}
//右が切れたら左にスワイプしてください
今回、構造体の中に文字列を宣言する方法をご紹介しました。一般的には文字列をポインタで宣言する場合が多いですが、並行して覚えることが増えると理解しづらくなりますので、まずはこのような宣言方法もあるんだなくらいに思ってもらえればと思います。
この入門ではまずはchar name[10]のような宣言を使用させて頂きます。
typedef
Typedefを使用するとデータ型の名前を好きなように付けることができます。
typedef 現データ型 新データ型実際の使用例を見てみます。
#include <stdio.h>
typedef unsigned int u_int;
main()
{
u_int a = 3;
printf("%d\n", a);
}
このtypedefを使用すれば「unsigned int」などを多用する時にすっきりと記述することができます。しかし、おそらく最も有名なtypedefの使い方は構造体のテンプレートの宣言です。以下のようにシンプルに表記することができます。
//typedefなし(従来)
struct man {
int ht;
int wt;
};
//structが必要
struct man taro;
struct man jiro;
struct man saburo;//typedefあり
typedef struct aaa {
int ht;
int wt;
} man;
//structは不要
man taro;
man jiro;
man saburo;
//上記のaaaは省略してもOK
//何を書いても無視される実際に使用してみます。⑳のソースコードをtypedefに変更します。
#include <stdio.h>
typedef struct human {
char name[10];
int age;
} man;
main()
{
//構造体変数の宣言と初期化
man taro = {"taro",20};
strcpy_s(taro.name, 10,"aki");
printf("%s\n", taro.name);
printf("%d\n", taro.age);
}
//右が切れたら左にスワイプしてください構造体の宣言の方法、使い方は理解してもらえましたか?不安な部分があったら、じっくり理解して次に進んでもらえればと思います。
goto文
goto文は結論からいうと良くない構文です。便利な反面、作成者以外の人が読んだときに非常に分かりづらくなるためです。
ラベル: //B
・
・
・
goto ラベル; //A
// AからBに飛びます使用例を見てみます。
#include <stdio.h>
main()
{
START:
for (i = 0; i < 3; i++)
printf("%d ", i);
}
goto START; //STARTへ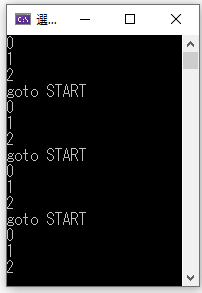
goto文はどうしても使用しないといけない場合は使用してもダメではありませんが、他に方法がないかを模索して可能な限り避けた方が無難です。
多次元配列
多次元配列とは今までの配列が1列に並べて値を管理していたと例えると2次元では縦・横の2方向、3次元では縦・横・高さの3方向に値を並べて管理する方法です。
型 配列名[要素数];
//1次元
//インデックス0, 1, 2
int a[3] = {10, 11, 12]
//2次元
int a[要素数][要素数] = {
{a, b, c・・・},
{d, e, f・・・}
};
//3次元
int a[要素数][要素数][要素数] = {
{a, b, c・・・},
{d, e, f・・・},
{g, h, k・・・}
};
//右が切れたら左にスワイプしてください2次元を表でご説明します。以下の値を代入するとします。
| 0 | 1 | 2 | |
| 0 | 10 | 11 | 12 |
| 1 | 20 | 21 | 22 |
//型 配列名[要素数][要素数]
int a[2][3] = {
{10, 11, 12},
{20, 21, 22}
};
//インデックスは0から始まるため
//a[1][2]まで格納される
//a[0][0] = 10;
//a[0][1] = 11;
//a[0][2] = 12;
//a[1][0] = 20;
//a[1][1] = 21;
//a[1][2] = 22;
変数の宣言時はa[2][3]としていますがインデックスで取り出す最大はa[1][2]までになります。これは宣言時は「要素数」を[]の中に記述して、実際に呼び出すインデックスは0から始まるためです。
実際に動作させてみます。
#include <stdio.h>
main()
{
//2次元
int a[2][3] = {
{10, 11, 12},
{20, 21, 22}
};
int i, j;
printf("1つずつ取り出す\n");
printf("a[0][0]=%d\n", a[0][0]);
printf("a[1][2]=%d\n", a[1][2]);
printf("for文で取り出す\n");
for (j = 0;j < 2;j++)
{
for (i = 0; i < 3; i++)
{
printf("a[%d][%d]=%d\n", j, i, a[j][i]);
}
}
}
//右が切れたら左にスワイプしてください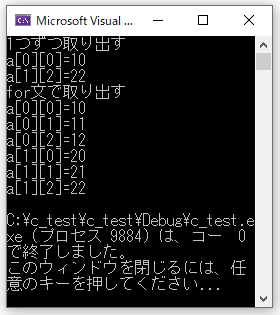
ちょっと複雑になりますが多次元配列を使用すると効率良くデータを管理できることがありますのでこういう方法もあるとだけ覚えてもらえればと思います。
ヘッダファイル
ヘッダファイルとは今まで最初に書いていた#include <stdio.h>のように拡張子が「.h」のファイルです。大量の関数などを「.c」のファイルに書き込まずにヘッダファイルに書き込んでおき、それらを取り込む(インクルード)ことで「.c」をシンプルにすることができます。このヘッダファイルは別の「.c」でも使いまわすことができますので効率良くプログラミングを行うことができます。ちなみに今まで最初に記述していた「stdio.h」をインクルードすることで「printf」などの関数を使用することができていました。前回作成した関数をヘッダファイルに移してみます。
//func.hの名前でファイルを作成
int max(int a, int b)
{
if (a >= b)
{
return a;
}
else
{
return b;
}
}
//この先に大量の関数を追加可能
//void A()
//{
// 処理;
//}
//float B(float a)
//{
// 処理;
//} ・・・
//右が切れたら左にスワイプしてください//標準ヘッダファイルは<>ではさむ
#include <stdio.h>
//自作ヘッダファイルは""ではさむ
#include "func.h"
main()
{
int a = 5;
int b = 7;
int c;
c = max(a, b);
printf("%d\n", c);
}
//右が切れたら左にスワイプしてくださいヘッダファイル(.h)とソースファイル(.c)を同じフォルダに入れてビルドして実行します。(Visual Studioのヘッダファイルに追加しても、しなくても同じフォルダに入れるとビルドできます)
ヘッダファイルを使用すると大規模なプログラミングを分担して行うこともでき、過去に作成した関数をそのまま使いまわすこともできます。ちなみにheaderなので「ヘッダー」と読みたいところですが、一般的には「ヘッダ」と伸ばさないのが一般的のようです。
define
defineは「マクロ」の1種です。マクロとは今まで最初に記述していた「#include」のように「#」で始まる記述のことですが、詳細は置いておき今回は「#define」の使い方のみをご紹介します。
#define RUN 0
//defineとRUNと0の間は
//半角スペースです
case 0:
case RUN:
//0をRUNに置き換えることが
//できるようになります実際の使用例をご紹介します。⑬のswitch文のプログラムを変更してみます。まずは変更前です。
#include <stdio.h>
main()
{
int a = 3;
switch(a)
{
case 0:
printf("%d\n", a);
break;
case 1:
printf("%d\n", a);
break;
default:
printf("それ以外\n", a);
}
}
//右が切れたら左にスワイプしてくださいdefineを使用してみます。
#include <stdio.h>
#define RUN 0
#define DEBUG 1
main()
{
int a = 3;
switch(a)
{
case RUN: //変更
printf("%d\n", a);
break;
case DEBUG: //変更
printf("%d\n", a);
break;
default:
printf("それ以外\n", a);
}
}
//右が切れたら左にスワイプしてください結果は同じですが、0や1よりも「RUN」「DEBUG」の方が動作を想像しやすいですね。defineを上手に活用して他の方が分かりやすいプログラミングを行ってください。
値渡しとポインタ渡し
今回はかなり難易度が高いのでポインタを十分理解されてから読まれることをお勧めします。関数に引数として変数を渡す時には「値渡し」と「ポインタ渡し」の2種類があります。ポインタ渡しは厳密には異なりますが「参照渡し」と呼ばれることもあります。まずは次のイメージと表でご説明します。
【値渡しのイメージ】
①1番地に太郎さんが住んでいた
②2番地に同姓同名の太郎さんが引っ越してきた
③2番地の太郎さんの名義が次郎さんに変わった(1番地の太郎さんは住み続けている)
| 名義 | 太郎(x) | 太郎(a=x) | → | 次郎(a=y) |
| 住所 | 1番地(&x) | 2番地(&a) | → | 2番地(&a) |
【ポインタ渡しのイメージ】
①1番地に太郎さんが住んでいた
②1番地の名義が太郎さんから次郎さんに書き換えられた
(1番地は次郎さんが住むことになった)
| 名義 | 太郎(x) | → | 次郎(y) |
| 住所 | 1番地(&x) |
値だけ関数に渡すのが値渡し、アドレスを関数に渡すのをポインタ渡しと呼びます。先述の通り、値渡しは値をコピー(x = a)しますが元のxと新しく作ったaは別に管理されます。それに対してポインタ渡しはアドレスを渡すので元の変数が書き換えられます。
実際の動作で2つの渡し方の違いを体感してもらいます。値渡しとポインタ渡しで引数を渡し、関数内ではもらった引数に5を代入して結果を比較します。
#include <stdio.h>
void value(int a); //値渡し
void pointer(int *a); //ポインタ渡し
main()
{
int x = 2;
printf("a=%d\n", x);
value(x); //値を渡す
printf("a=%d\n", x);
pointer(&x;); //アドレスを渡す
printf("a=%d\n", x);
}
//値渡し確認用関数
void value(int a)
{
a = 5; //引数に5を代入
}
//ポインタ渡し確認用関数
void pointer(int *a)
{
//そのアドレスに格納されている
//値に5を代入
*a = 5;
}
//右が切れたら左にスワイプしてください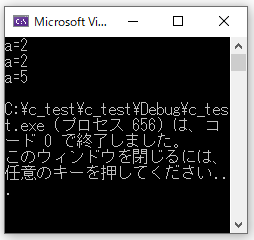
初めて見られた方は意味不明かもしれません。2つの関数内で引数に5を代入しましたが、値渡しでは元のxが書き変わらず、ポインタ渡しではxが書き換えられていますね。
値渡しでは新たにaという変数を作ってxの値だけをコピーしているため関数内でaを書き換えても元のxには全く影響を与えません。
しかし、ポインタ渡しはxのアドレスを渡すため&xとa(ポインタ)は全く同じアドレスになります。そのため*aを書き換えられるとxの値も変更されてしまいます。
C言語でポインタ渡しは多くの方が挫折するポイントですが、混乱しそうになったら最初の2つの表をじっと見てもらえればと思います。ポインタで悩みそうになったら、紙にポインタとその値を1度書いて落ち着いてもらうと理解しやすいかと思います。
開発環境のセットアップ
C言語のテストを行うための開発環境をご紹介します。今回の独学C言語入門では「Microsoft Visual Studio」を使用したいと思います。以下のリンクから「無料ダウンロード」をクリックしてダウンロードしたexeを実行してインストールをお願いします。このVisual Studioは全ての内容をダウンロードすると重すぎますので途中で聞かれたらとりあえず今回は「C++によるデスクトップ開発」にだけチェックを入れてインストールをお願いします。それでも重いのでダウンロードやインストール完了までにお時間がかかります。最後に再起動を指示されますので1度再起動をしてください。
正常にインストールが完了したら実際にVisual Studioでプログラミングを行い、実行するまでの流れをご紹介します。まずはVsual Studioを起動してください。起動時にログインを求められますがログインしてもいいですし、「後で行う」を選んで次に進んでも大丈夫です。そして赤枠の「新しいプロジェクトの作成」をクリックしてください。
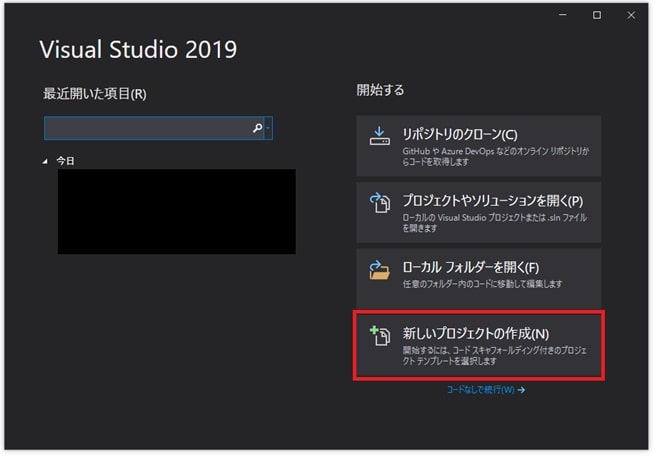
赤枠の「空のプロジェクト」を選択し、右下の「次へ」をクリックします。
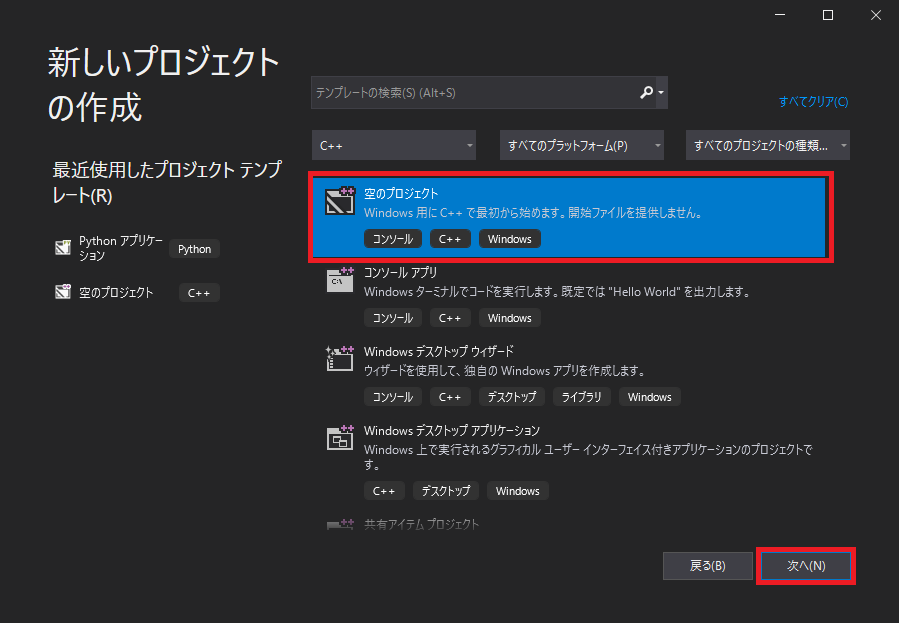
プロジェクト名に「c_test」と入力し、場所は「C:¥」とCドライブの直下を選択しました。お好きなプロジェクト名や場所を選択してもらって構いませんが、パスに日本語は使用せず半角英数にされることをお勧めします。(パスによってはエラーが発生する場合があります)
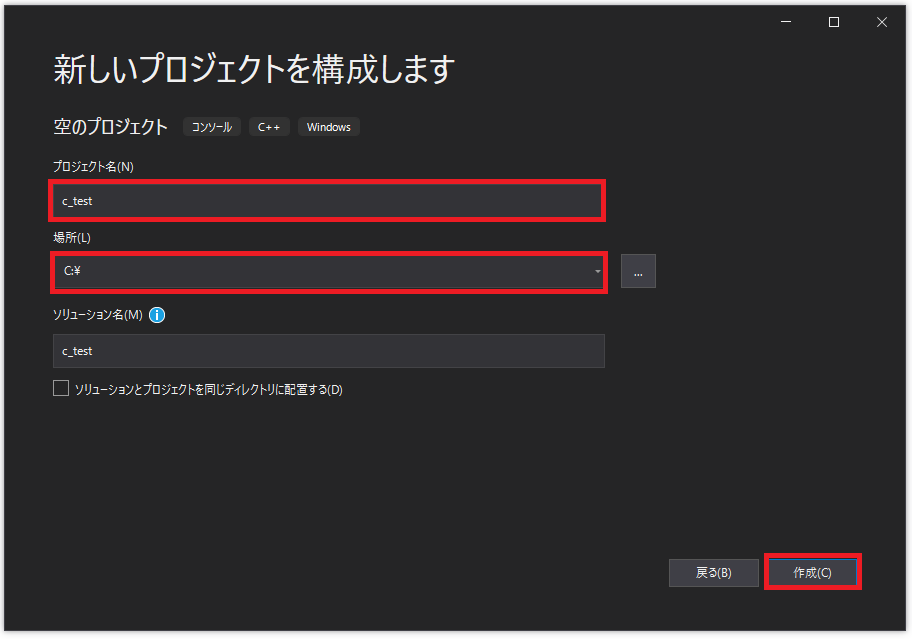
右側の「ソリューションエクスプローラー」の「ソースコード」を右クリックします。
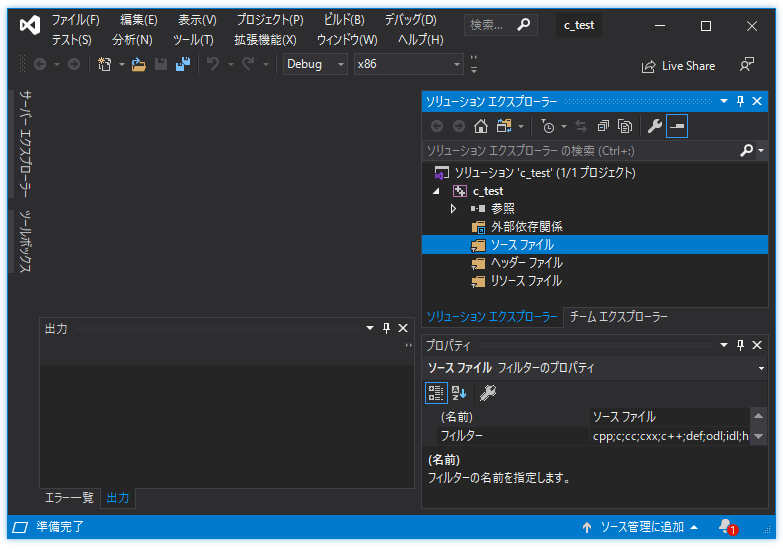
「追加」→「新しい項目」をクリックします。
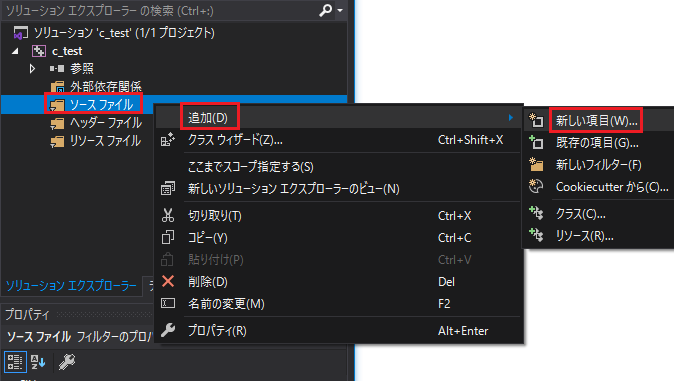
「C++ファイル(.cpp)」を選択し、ファイル名を「hello_world.c」にします。ファイル名は何でもいいのですが、拡張子を必ず「.c」に書き換えて「追加」をクリックします。
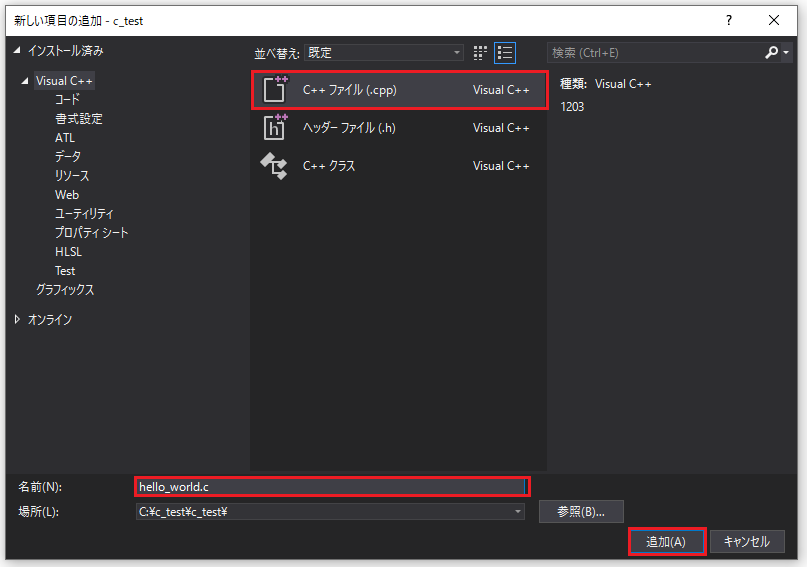
ソースファイルに「hello_world.c」が追加されました。これでプログラミングを開始できます。
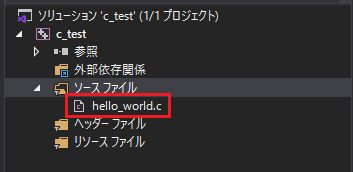
40年前に始まったとされる伝説的なフレーズ「Hello, World」を表示するソースコードを記入します。コピーペーストしてもらってもOKです。最後に「\n」となっている部分は「¥n」です。このサイトのエディタもですが、エディタによっては「\n」になってしまうのですが動作に問題はありません。
#include <stdio.h>
main()
{
printf("Hello, World\n");
}
// \nは「¥n」です。半角で
// 入力してください
//#include<stdio.h>はprintfを
//使用するためのヘッダーファイルちなみにVisual Studioを使用すると次の画像のように「¥n」と表示してくれます。
上のメニューにある「ビルド」→「ソリューションのビルド」をクリックします。
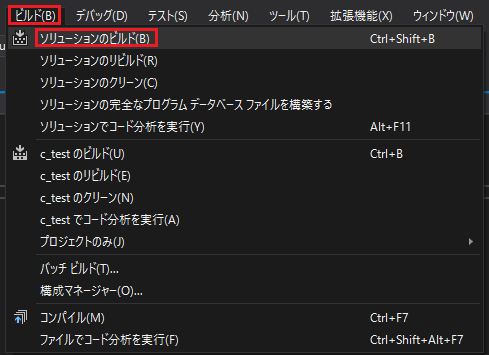
成功すると左下のウィンドウに「ビルド:1 正常終了」と表示されます。失敗した場合はソースコードを確認してください。
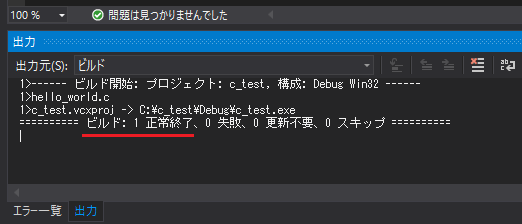
実際に実行してみます。上のメニューの「デバッグ」→「デバッグなしで開始」をクリックしてください。
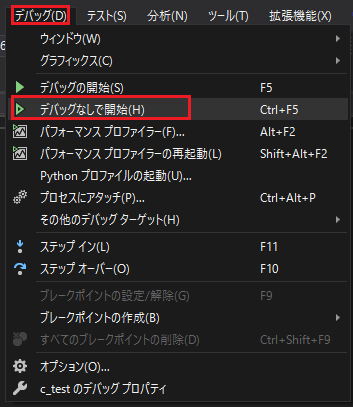
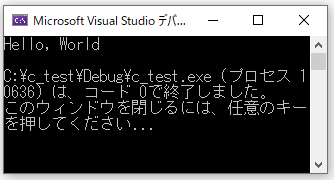
黒いウィンドウが立ち上がり「Hello, World」と表示されると成功です。ここまでがVisual StadioでC言語を実行するまでの流れになります。
次に別のテストを行うために新しくソースコードを作成したい場合をご説明します。右側の「ソリューションエクスプローラー」のソースファイルの「hello_world.c」を右クリックして「削除」をクリックします。
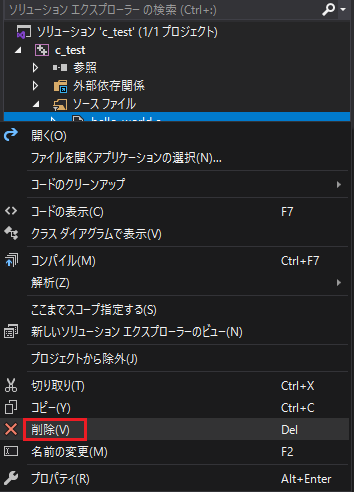
「除外」をクリックしてください。(2度と「hello_world.c」を使用しないので削除しても良いということであれば「削除」をクリックしてもOKです)「hello_world.c」はプロジェクトから外されました。
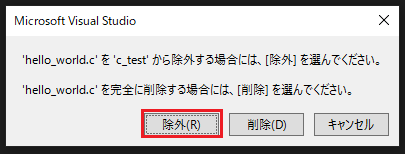
そして、先ほどご説明しましたが、「ソリューションエクスプローラー」を右クリック、「追加」→「新しい項目」で新しいソースファイルを追加します。