
C++を学習する前にお伝えしたい重要なこと
エンジニア歴15年のうましです。C++をこれから学習する方にアドバイスさせて頂きたいことがあります。
・C++をマスターしようと考えないこと
・完全に理解できなくてもとりあえず進む
上記の2点はC++を学習する際に非常に重要だと感じますので、最初にご紹介しておきます。
C++をマスターしようと考えないこと
「C++をこれから勉強してマスターする気満々なのにどういうこと??」
そう感じさせてしまったかもしれません。最初にお伝えしておきますが、
C++は非常に高度で範囲が広く全域をマスターするのは限りなく不可能に近い言語です。さらに3年ごとに標準規格が更新されるので進化する速度も早いです。
他の言語も完璧にマスターし、使いこなすのは大変ですが、C++を極めようと考えるのは、書道や武道のような『道』を生涯にわたって極めるくらいの継続力や思い入れが必要で、現役のエンジニアでもC++を全域にわたって理解するのは限りなく不可能に近い言語ということをまずは理解しておくことが大切です。
完全に理解できなくてもとりあえず進む
他のプログラミング言語も同様ですが、理解しづらい『壁』に必ずぶつかります。
「オブジェクトって何?」
「ポインタが理解しづらい・・・」
「なぜこの変数はポインタで宣言するの?」
僕もC言語やC++を学習し始めた頃だけでなく、今でもそのような部分には遭遇します。これらの不明な点を完全に理解しようとして苦痛に感じ、全てが嫌になりプログラミングをやめてしまいたくなることもあります。そうなるくらいであれば、
「そういうもの」
「とりあえず理解ではなく暗記しておくか」
これくらいの気持ちでいた方が挫折のリスクは大幅に下がります。最初はうまく理解できなくても学習を継続する中で、ある瞬間に
(あ、そういうことか)
と点と点がつながり理解できる時が来ます。しっかりと理解できない部分があっても、「こういうもの」と、一旦保留にして先に進むことを強くおすすめします。
C++はあくまでツール
C++はあくまでツールです。英語学習も辞書を全て暗記したり理解する必要がないように、必要な部分だけ理解すれば、実務レベルでも十分活用できます。例えば、Arduinoというハードウェアでは『Arduino語』と呼ばれる言語が使用されますが、中身はC++をライブラリ化して複雑な部分を隠して初心者でも簡単にプログラミングできるようにしています。C++を使った実務でもポインタの知識すら必要ない場合もあります。
「そんな考えではC++の本質、重要な部分は理解できないのでは?」
このような厳しいご意見を頂くかもしれません。しかし、まずはC++に慣れ親しんで、挫折のリスクを下げるのが重要だと感じます。C++はそれほど複雑で高度な言語です。
この独学入門では、C++のほんの一部、ごく初歩の部分だけ扱いますが、基礎を通じて難易度が高く避けられることが多いC++でのプログラミングを経験しながら「C++は楽しいな」と感じてもらうことを目的にしています。C++は極めるのは非常に困難ですが「必要な部分だけ理解できれば良いや」くらいの気持ちで学習をスタートすることをおすすめします。
このC++独学入門ではこのサイトの『C言語入門』のレベルくらいを理解している方を対象にしています。まずは、C言語の基礎を理解してもらい、こちらのページでC++を学習してもらうことをおすすめします。
Hello World
まずは、お決まりのワードではありますが『Hello World』を表示してみます。比較のために最初にC言語で記述してみます。
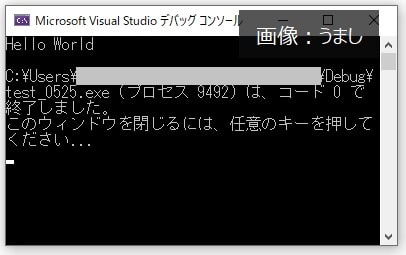
#include <stdio.h> //printfを使用するためのヘッダーファイルを読み込む
int main()
{
printf("Hello World\n"); // \nは改行の意味
return 0; //main関数の戻り値を0
}
かんたんに解説すると、文章を表示するための『printf関数』を使用するために1行目の
#include <stdio.h>この記述が必要になります。これを忘れて、インクルードしないとprintf関数を使用できないのでエラーになりますね。最後の
return 0; これは、とりあえず決まり文句と覚えてもらっても大丈夫ですが、少し踏み込むとint型で定義されているmain関数が正常に終了したという意味で戻り値として0を返すという意味になります。『return 0;』はなくてもコンパイルは通りますが、警告が出ることがあります。
それでは、次にC++での書き方をご紹介します。printf関数を使用することもできますが、C++では標準出力ストリームを利用することが一般的です。
#include <iostream>
int main()
{
std::cout << "Hello World" << std::endl; //endlは改行の意味
return 0;
}
さらに1行追加することでより簡単に書くことが可能です。
#include <iostream>
using namespace std; //追加
int main()
{
cout << "Hello World" << endl; //std::が省略できる
return 0;
}続けて文章を出力するならこのように記述します。
#include <iostream>
using namespace std; //追加
int main()
{
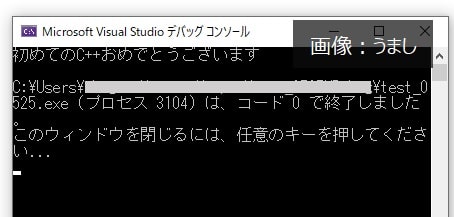
cout << "初めてのC++" << "おめでとうございます" << endl;
return 0;
}
C++のプログラミングお疲れ様でした。少しずつC++に慣れながら楽しんで学習してもらえればと思います。
string
C言語では、文字列を変数に格納する場合は次のように定義する必要がありました。
//以下の2つは同じこと
char str[] = "apple"; //[]内を省略してもOK
char str[6] = "apple"; //5文字+NULLの6文字の配列しかし、この文字列を変更する際には注意が必要でした。
#include <stdio.h>
#include <string.h> //このヘッダーのインクルードが必要
int main(void)
{
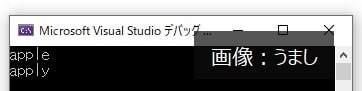
char str[] = "apple"; //文字列を宣言
printf("%s\n", str);
// str = "apply"; //代入では変更不可(エラーが発生)
strcpy_s(str, 6, "apply"); //strcpy_s関数を使用して変更する
printf("%s\n", str);
return 0;
}
strcpy_sを使用するのはちょっと手間ではありました。しかし、C++では文字列クラス(文字列変数)の『string』を使用することができます。
#include <iostream>
#include <string> //このヘッダーのインクルードが必要
int main(void)
{
std::string str = "apple"; //string型で変数を宣言
std::cout << str << std::endl;
str = "apply"; //代入で変更が可能
std::cout << str << std::endl;
return 0;
}『using namespace std;』を追加すると『std::』を省略できるので追記しておくことをおすすめします。
#include <iostream>
#include <string> //このヘッダーのインクルードが必要
using namespace std; //追加すると『std::』を省略できてすっきり
int main(void)
{
string str = "apple"; //string型で変数を宣言
cout << str << endl;
str = "apply"; //代入で変更が可能
cout << str << endl;
return 0;
}string型は代入が簡単なだけではありません。クラスについては後ほどご紹介しますが、stringクラスはメソッドも持っているので、次のような使い方もできます。文字列を足し合わせるのも簡単です。
#include <iostream>
#include <string> //このヘッダーのインクルードが必要
using namespace std; //名前空間指定。追加すると『std::』を省略できてすっきり
int main(void)
{
string str1; //string型で変数を宣言
string str2; //string型で変数を宣言
cout << str1.empty() << endl; //str.empty 0:値を格納済み / 1:空
str1 = "apple";
str2 = "banana";
cout << str1 << endl;
cout << str2 << endl;
str1 = str1 + str2; //文字列を足し合わせる
cout << str1 << endl;
cout << str1.size() << endl; //文字列の数(サイズ)を測定
cout << str1.empty() << endl;
return 0;
}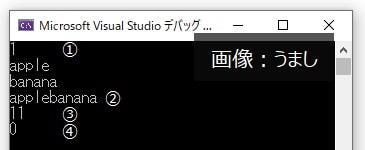
①str1が空なので『1』
②文字列を足し合わせた結果
③②の文字列の数(サイズ)
④str1の中に値が格納されているので『0』
まずは、「C++では文字列にはchar型ではなく、stringクラスを使用するのか」くらいから理解を始めて少しずつ慣れると良いかと思います。
クラス
C++はオブジェクト指向のプログラミング言語です。
オブジェクト指向で非常に重要なものが『クラス』というものです。C言語やC++を使用した実務でも意外にポインタは使用しない、もしくは使用しなくてもプログラミングできることもありますが、C++で加わったクラスという考え方は必須な場合が多く、最重要と言っても過言ではないかと思われます。
クラスとは、データと関数をまとめている型のことで、C言語に慣れている方なら構造体に関数(メソッド)を加えたものをイメージすると理解しやすいかと思います。
言葉だけではイメージしづらいので『ヒト(human)』を想像してみます。ヒトは次のようなデータメンバー変数を持っています。
・名前(name)
・身長(ht)
・体重(wt)
これをC言語の構造体で表現すると次のようになります。
struct human {
char* name;
int ht;
int wt;
};クラスは、C言語の構造体で持つことができなかった関数を加えることができます。次のような動作を加えることにします。
・食べる(wtが1増える)
・運動する(wtが1減る)
これらのクラス内で持つことができる関数をメソッド(メンバー関数)と呼びます。実際にコードにしてみます。
class human {
double ht;
double wt;
public:
void Eat()
{
wt++;
}
void Exe()
{
wt--;
}
void SetData(int height, int weight) //htやwtを変更するには関数を使用する
{
ht = height;
wt = weight;
}
};クラスは非常に重要なのでしっかりと理解するようにしてください。
アクセス制御(private・public・protected)
C++に限らずクラスを使用するオブジェクト指向と呼ばれるプログラミング言語ではアクセシビリティ(アクセス制御)という考え方があります。前回の項で使用したHumanクラスのメンバーをシンプルにして解説します。
class human {
//private: //『private:』は省略できる。ここから下は直接操作できない
int ht;
int wt;
public: //publicより下のデータ変数やメソッドは操作可能
void SetHt(int num) //htを変更するメンバー関数
{
ht = num;
}
void Setwt(int num) //wtを変更するメンバー関数
{
wt = num;
}
}; 基本的には、メンバー変数はprivate、メソッド(メンバー関数)はpublicで設定する必要があります。その理由はまた後ほど詳しく解説します。また、後からできてきますが、『継承』と呼ばれるクラスを元に派生クラスを作成する場合は、privateをprotectedに変更する必要があります。
クラスと構造体の違い
C言語では構造体に関数を加えることはできませんでしたが、実がC++では構造体の中にも関数を加えることができるので、クラスと構造体の違いはほとんどなくなっていますが、クラスと構造体のはっきりとした違いもあります。
クラスの項目でご紹介した『private』や『public』のようなメンバーのアクセスに関するデフォルト(標準)の設定が異なります。
・クラスは未設定の場合はメンバーが『private』
・構造体は未設定の場合はメンバーが『public』
クラスと構造体に大きな違いはないものの、特にこだわりがなければC++ではクラスを使用することをおすすめします。
インスタンス
クラスは、オブジェクトがどんなメンバーを保有しているかの設計図でしかありません。そのため、実体化(インスタンス化)する必要があります。クラスの項で作成したhumanクラスを実際にインスタンス化して使用してみます。
#include <iostream>
using namespace std; // 名前空間指定
class human {
double ht;
double wt;
public:
void Eat() {
wt++;
}
void Exe() {
wt--;
}
void SetData(int height, int weight) {
ht = height;
wt = weight;
}
void ShowData() {
cout << ht << "cm" << endl;
cout << wt << "kg" << endl;
}
};
int main(void)
{
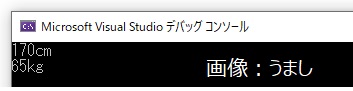
human taro; //humanクラスのtaroを生成(インスタンス化)
taro.SetData(170, 65);
taro.ShowData();
}
カプセル化・メンバー変数を直接制御してはいけない理由
プログラミングを学習している方は、1度はこのような疑問を持ったことがあるのではないでしょうか?
メンバー変数を直接操作すれば簡単なのに、なぜわざわざ関数を利用して変数をセットするの?
身長(ht)というメンバー変数を持つHumanクラスを元に解説すると
//メンバー変数をメソッドでセットする方法(一般的)
class human {
int ht; //private
public:
void SetHt(int num) {
ht = num;
}
};
・
・
・
taro.Setht(170); //なぜわざわざ関数にするの?
//メンバー変数を直接操作する方法
class human {
public:
int ht; //htをpublicにしてアクセス可能にする
};
・
・
・
taro.ht = 170; //こっちが楽じゃない?実は僕もC++を学習し始めた頃は同じことを感じていました。結論からお伝えすると、メンバー変数を直接操作することは危険なので行ってはいけません。
この例で、コードの作成者のあなたは、身長(ht)の単位はセンチでの入力を想定していたとします。しかし、別の人が勘違いをして、メートルで入力したらどうでしょうか?正しい動作を実現することができません。
他にもキーボードを打ち間違えてマイナスの値を入力したり、10や280(センチ)など一般的な身長の値から明らかに外れた値を入力する可能性もあります。これが数十行程度のコードなら不具合を発見するのは難しくはありませんが、何千行、何万行ものコードだったら1行のミスを探すのも困難です。
関数(メソッド)で変数を設定する方法あれば、誤入力を防止するためにこのような書き方もできます。
#include <iostream>
using namespace std;
class human {
int ht; //省略した場合はprivate
public:
void SetHt(int num) {
if ((50 < num) && (num < 200)) //誤入力防止
{
ht = num;
cout << "set_OK, ht=" << ht << endl;
}
else
{
cout << "set_NG, 50~200(センチ)の範囲で入力してください" << endl;
}
}
};
int main()
{
human taro;
taro.SetHt(170);
taro.SetHt(1.7);
// taro.ht = 170; //htに直接アクセスできないのでエラーになる
}
ミスを防止するためにメンバー変数はprivateにしておいて直接のアクセスを不可にしておくのは重要です。よほどの事情がなければ基本的にはメソッドから操作する必要があります。
コンストラクタ・デストラクタ
コンストラクタとは、オブジェクトが生成される際、自動的に呼び出されるメソッドです。デストラクタは、コンストラクタと逆にオブジェクトが破棄される時に自動的に呼び出されるメソッドです。コンストラクタとデストラクタは、publicで記述しないとエラーになります。
コンストラクタはクラスと同じ名前、デストラクタは『~(チルダ)』を前に付けます。戻り値はありませんが、voidも付けません。
それでは、実際のコードで動作を確認してみます。
#include <iostream>
#include <string>
using namespace std;
class Human {
string name;
int ht = 0;
int wt = 0;
public:
//コンストラクタ。クラスと同じ名前。戻り値はないが、voidは付けない。
Human() {
cout << "Humanクラスを生成" << endl;
}
//デストラクタ。クラス名の前に『~(チルダ)』。戻り値はないが、voidは付けない。
~Human() {
cout << "Humanクラスを破棄" << endl;
}
//設定されている名前,身長,体重を出力
void Show_Data() {
cout << name << "," << ht << "," << wt << endl;
}
//名前、身長、体重を一括で設定する関数(メソッド)
void Init_Set(string str, int num1, int num2) {
name = str;
ht = num1;
wt = num2;
}
};
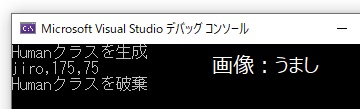
int main()
{
Human taro;
taro.Init_Set("jiro", 175, 75);
taro.Show_Data();
}
継承
すでに作成したクラスを元に、新しいクラスを作成することを継承と呼びます。元になるクラスを親クラス(基底クラス)、継承して作成したクラスを子クラス(派生クラス)と呼びます。簡単なコードで継承の動作を確認してみます。
名前、身長、体重のデータ変数を持ち、食べると体重が1kg増えるHumanクラス(親クラス)を元に継承して、走ると体重が1kg減るR_manクラス(子クラス)を作成します。
| 親クラス:Human | 子クラス:R_man |
| メンバー変数 | |
| 名前 | 名前 |
| 身長 | 身長 |
| 体重 | 体重 |
| メソッド(メンバー関数) | |
| 食べる(体重+1kg) | 食べる(体重+1kg) |
| 走る(体重-1kg)※追加 | |
継承をする場合、親クラスのprivateのメンバーに子クラスはアクセスできません。そのため、子クラスから親クラスのメンバーにアクセスができ、外からはアクセスできない『protected』で親クラスのprivateのメンバーを設定する必要があります。
#include <iostream>
#include <string>
using namespace std;
class Human {
protected: // ※1 派生したクラスも扱えるようにprivate→protectedに変更
string name;
int ht;
int wt;
public:
void Set_name(string str) { name = str; }
void Set_ht(int num) { ht = num; }
void Set_wt(int num) { wt = num; }
//設定されている名前,身長,体重を出力
void Show_Data() {
cout << name << "," << ht << "," << wt << endl;
}
//名前、身長、体重を一括で設定する関数(メソッド)
void Init_Set(string str, int num1, int num2) {
name = str;
ht = num1;
wt = num2;
}
void Eat() { //食べると体重(wt)が1増える
cout << name << "_eat" << endl;
wt++;
}
};
class R_man : public Human { //継承
public:
void Run() { //走ると体重(wt)が1減る『RUN()』を追加
cout << name << "_run" << endl;
wt = wt--; // ※1をprotectedにすることでアクセス可能になる
}
};
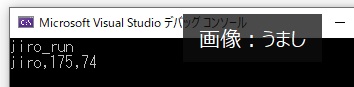
int main()
{
R_man jiro; //Human型を継承した派生クラスのR_man型の『jiro』を生成
jiro.Init_Set("jiro", 175, 75);
jiro.Run(); //親クラスのHuman型ではなかった『Run();』を実行可能
jiro.Show_Data();
}
継承時のメソッドの再定義
継承を行う時、親クラスのメソッド(メンバー関数)を、子クラスで再定義することができます。再定義を行うには、関数名、引数、戻り値が親クラスと子クラスで同じである必要があります。
名前、身長、体重のデータ変数を持ち、食べると体重が1kg増えるHumanクラスを元に継承して、食べると5kg増えるR_manクラスを作成します。
| 親クラス:Human | 子クラス:R_man |
| メンバー変数 | |
| 名前 | 名前 |
| 身長 | 身長 |
| 体重 | 体重 |
| メソッド(メンバー関数) | |
| 食べる(体重+1kg) | 食べる(体重+5kg)※再定義 |
#include <iostream>
#include <string>
using namespace std;
class Human {
protected: // ※1 派生したクラスも扱えるようにprivate→protectedに変更
string name;
int ht;
int wt;
public:
void Set_name(string str) { name = str; }
void Set_ht(int num) { ht = num; }
void Set_wt(int num) { wt = num; }
//設定されている名前,身長,体重を出力
void Show_Data() {
cout << name << ",ht=" << ht << ",wt=" << wt << endl;
}
//名前、身長、体重を一括で設定する関数(メソッド)
void Init_Set(string str, int num1, int num2) {
name = str;
ht = num1;
wt = num2;
}
void Eat() { //食べると体重(wt)が1増える
cout << name << "_eat(Human)" << endl;
wt = wt++;
}
};
class R_man : public Human { //継承
public:
void Eat() { //R_manのEatは体重(wt)が2増える(Eat関数の再定義)
cout << name << "_eat(R_man)" << endl;
wt = wt + 5;
}
};
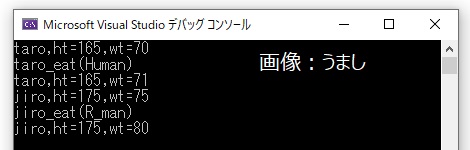
int main()
{
Human taro; //Human型の『taro』を生成
taro.Init_Set("taro", 165, 70);
taro.Show_Data();
taro.Eat(); //Humanクラスはwt+1
taro.Show_Data();
R_man jiro; //Human型を継承した派生クラスのR_man型の『jiro』を生成
jiro.Init_Set("jiro", 175, 75);
jiro.Show_Data();
jiro.Eat(); //R_manクラスはwt+5
jiro.Show_Data();
}
new・delete演算子
ここまでは、クラスからインスタンス化(オブジェクトの生成)する時は、変数を宣言するように静的に生成をしていました。
class Human {
string name;
int ht;
int wt;
・
・
・
};
int main()
{
Human taro; //静的にHuman型のオブジェクト『taro』を生成
・
・
・
}実際にプログラミングでは、使うか使わないか分からないようなオブジェクト、実際に動作しないと必要か分からないオブジェクトというものがあります。その場合は、必要な時に空いたメモリのスペースを利用してオブジェクトを生成します。このような挙動を動的にオブジェクトを生成すると言います。
こうすることで、メモリの無駄遣いを減らすことができます。この動的なオブジェクトを生成する方法がnewを使用する方法です。そして、使用後にはdeleteでオブジェクトを破棄します。newとdeleteはセットです。
//Humanクラスのポインタを宣言。new演算子でHumanクラスのオブジェクトが入る場所を確保
Human *h_add = new Human;
h_add = &taro;
・
・
・
delete h_add; //使用後は、h_addをdelete(破棄)
Human *h_add = new Human; //破棄したポインタは同じ名前で生成できる
h_add = &jiro; 実際にnewとdeleteを使って動きを確認してみます。
#include <iostream>
#include <string>
using namespace std;
class Human {
string name;
int ht;
int wt;
public:
void Set_name(string str) { name = str; }
void Set_ht(int num) { ht = num; }
void Set_wt(int num) { wt = num; }
//名前、身長、体重を一括で設定する関数(メソッド)
void Init_Set(string str, int num1, int num2) {
name = str;
ht = num1;
wt = num2;
}
//設定されている名前,身長,体重を出力
void Show_Data() {
cout << name << "," << ht << "," << wt << endl;
}
};
int main()
{
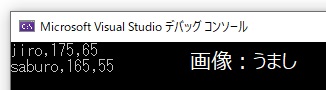
Human *h_add = new Human; //Human型のポインタ(アドレス)をnewで生成
h_add->Init_Set("jiro", 175, 65); //データ(メンバー変数)を一括で設定
h_add->Show_Data();
delete h_add; //h_addをdelete(破棄)
h_add = new Human; //同じ名前(h_add)で再度メモリ領域を確保
h_add->Init_Set("saburo", 165, 55); //データ(メンバー変数)を一括で設定
h_add->Show_Data();
delete h_add; //h_addをdelete(破棄)
}
親クラスのポインタに子オブジェクトを代入するメリット
C++は不思議な方法でオブジェクトを生成することがあります。初心者の方が理解しづらい考え方に
・ポインタ(アドレス)は親クラス(基底クラス)
・オブジェクトは子クラス(派生クラス)
このようなオブジェクトの宣言の方法があります。
//Human:親クラス
//R_man:Humanから継承で派生した子クラス
R_man taro; //オブジェクトは子クラス
Human *taro_add; //アドレス(ポインタ)は親クラス
taro_add = &taro //親クラスのポインタに子クラスのアドレスを格納ポインタやオブジェクトをしっかり理解していないと「なんのこっちゃ」かもしれません。
親クラス、子クラスのどちらかで統一して良いのでは?なぜ分けるのか?
C++を学習したばかりの方はそう感じるかと思います。実は僕もそうでした。しかし、このアドレスは親クラス、オブジェクトは子クラスという形式にするとすごく便利なことがあるのです。
親クラスと子クラスのメンバーを利用することができるからです。
先ほど、『再定義』の項で、継承すると同じ名前、引数、戻り値のメソッド(メンバー関数)は子クラスで再定義されることをお伝えしました。つまり、普通にオブジェクトを生成すると親クラスのメソッドは子クラスのメソッドで再定義(上書き)されているので、利用することができないのです。
『再定義』の項のコードを元に解説します。
| 親クラス:Human | 子クラス:R_man |
| メンバー変数 | |
| 名前 | 名前 |
| 身長 | 身長 |
| 体重 | 体重 |
| メソッド(メンバー関数) | |
| 食べる(体重+1kg) | 食べる(体重+5kg)※再定義 |
| 走る(体重-1kg) | |
しかし、親クラスのポインタをアドレスに使用することで『->(アロー演算子)』からアクセスすると、子クラスからも親クラスのメソッドも利用することができます。実際にコードで確認してみます。
#include <iostream>
#include <string>
using namespace std;
class Human {
protected: // ※1 派生したクラスも扱えるようにprivate→protectedに変更
string name;
int ht = 0;
int wt = 0;
public:
//設定されている名前,身長,体重を出力
void Show_Data() {
cout << name << "," << ht << "," << wt << endl;
}
//名前、身長、体重を一括で設定する関数(メソッド)
void Init_Set(string str, int num1, int num2) {
name = str;
ht = num1;
wt = num2;
}
void Eat() { //食べると体重(wt)が1増える
wt = wt++;
}
};
class R_man : public Human { //継承(子クラス)
public:
void Eat() { //R_manのEatは体重(wt)が5増える(再定義)
wt = wt + 5; //
}
void Run() { //Runを実行するとwtが1kg減る
wt--;
}
};
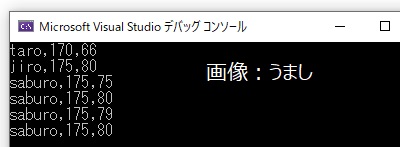
int main()
{
Human taro; //Humanクラスのtaroを生成
taro.Init_Set("taro", 170, 65);
taro.Eat(); //wtを+1
taro.Show_Data();
R_man jiro; //Humanクラスから派生したR_manクラスのjiroを生成
jiro.Init_Set("jiro", 175, 75);
jiro.Eat(); //再定義されたのでwtを+5
jiro.Show_Data();
//親クラスのポインタに子オブジェクトを代入
Human *saburo_add; //親クラス(Humanクラス)のポインタ
R_man saburo; //子クラス(R_manクラス)のオブジェクト
saburo_add = &saburo;
saburo.Init_Set("saburo", 175, 75);
saburo.Show_Data();
saburo.Eat(); //子クラスで再定義された後のEat();を実行できる wtを+5
saburo.Show_Data();
saburo.Run(); //子クラスで追加したメソッドも実行できる wtを-1
saburo.Show_Data();
saburo_add->Eat(); //ポインタからアクセスすると再定義前の親クラスのEat();も実行できる wtを+1
saburo.Show_Data();
}
ポインタをしっかりと理解していないと、オブジェクトは子クラス、アドレスは親クラスという形のメリットは理解しづらいかもしれません。理解するのが苦しくなったら、無理はせずにちょっと離れて、ポインタに慣れてからまたここは学習することをおすすめします。
仮想関数
前の項で、親クラスのポインタに代入した子クラスのメソッドを呼び出す場合、再定義される前の親クラスのメソッドが呼び出されることはご紹介しました。しかし、親クラスのポインタからアクセスしても、子クラスのメソッドを呼び出したい場合、仮想関数と呼ばれる状態にしておく方法があります。
『virtual』を記述します。仮想関数にして、子クラスで再定義することを、オーバーライドと呼びます。前回の『親クラスのポインタに子オブジェクトを代入するメリット』のコードにvirtualを追加しただけで結果が変わることを確認してもらえるかと思います。
#include <iostream>
#include <string>
using namespace std;
class Human {
protected: // ※1 派生したクラスも扱えるようにprivate→protectedに変更
string name;
int ht = 0;
int wt = 0;
public:
//設定されている名前,身長,体重を出力
void Show_Data() {
cout << name << "," << ht << "," << wt << endl;
}
//名前、身長、体重を一括で設定する関数(メソッド)
void Init_Set(string str, int num1, int num2) {
name = str;
ht = num1;
wt = num2;
}
virtual void Eat() { //Vritualを追記して、仮想関数にする。
wt = wt++;
}
};
class R_man : public Human {
public:
void Eat() { //Eat関数をオーバーライド
wt = wt + 5; //R_manのEatは体重(wt)が5増える
}
void Run() {
wt--;
}
};
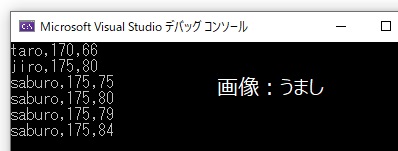
int main()
{
Human taro; //Humanクラスのtaroを生成
taro.Init_Set("taro", 170, 65);
taro.Eat(); //wtを+1
taro.Show_Data();
R_man jiro;
jiro.Init_Set("jiro", 175, 75); //Humanクラスから派生したR_manクラスのjiroを生成
jiro.Eat(); //再定義されたのでwtを+5
jiro.Show_Data();
//親クラスのポインタに子オブジェクトを代入
Human *saburo_add; //親クラス(Humanクラス)のポインタ
R_man saburo; //子クラス(R_manクラス)のオブジェクト
saburo_add = &saburo;
saburo.Init_Set("saburo", 175, 75);
saburo.Show_Data();
saburo.Eat(); //子クラスで再定義された後のEat();を実行できる wtを+5
saburo.Show_Data();
saburo.Run(); //子クラスで追加したメソッドも実行できる wtを-1
saburo.Show_Data();
saburo_add->Eat(); //ポインタからアクセスしても再定義後の子クラスのEat();を実行する wtを+5
saburo.Show_Data();
}
純粋仮想関数
親クラスを作成している段階で、「メソッドをどうしようかな?」と、まだ具体的なメソッド(仮想関数)が決まっていないことがあります。継承して子クラスで再定義する前提で使用する場合は、純粋仮想関数を使用します。純粋仮想関数を1つでも含むクラスは、オブジェクトを生成することができないので注意してください。
実際のコードで確認してみます。
#include <iostream>
#include <string>
using namespace std;
class Human {
protected: // ※1 派生したクラスも扱えるようにprivate→protectedに変更
string name;
int ht = 0;
int wt = 0;
public:
//設定されている名前,身長,体重を出力
void Show_Data() {
cout << name << "," << ht << "," << wt << endl;
}
//名前、身長、体重を一括で設定する関数(メソッド)
void Init_Set(string str, int num1, int num2) {
name = str;
ht = num1;
wt = num2;
}
virtual void Eat() = 0; //純粋仮想関数の記述方法
};
class R_man : public Human {
public:
void Eat() { //親クラスの純粋仮想関数を再定義
wt = wt + 5;
}
void Run() {
wt--;
}
};
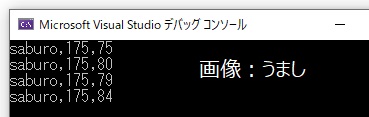
int main()
{
// Human taro; //Humanクラスは抽象クラスなのでオブジェクトを生成できない
//親クラスのポインタに子オブジェクトを代入
Human *saburo_add; //親クラス(Humanクラス)のポインタ
R_man saburo; //子クラス(R_manクラス)のオブジェクト
saburo_add = &saburo;
saburo.Init_Set("saburo", 175, 75);
saburo.Show_Data();
saburo.Eat(); //子クラスで再定義された後のEat();を実行できる wtを+5
saburo.Show_Data();
saburo.Run(); //子クラスで追加したメソッドも実行できる wtを-1
saburo.Show_Data();
saburo_add->Eat(); //ポインタからアクセスしても再定義後の子クラスのEat();を実行する wtを+5
saburo.Show_Data();
}
参照
C++は、変数に別の名前を付けてアクセスすることが可能です。これは参照と呼ばれる機能です。
int &a = b; //bの別名としてaを定義する(aとbは同じアドレス)実際のコードで参照をテストしてみます。山田花子さんの年齢を『hanako_age』と定義し、合わせて『yamada_age』も定義しますが、この2つはどちらも山田花子さんの年齢を表す同じもの(アドレスも同じ)です。
実際の動きをコードで確認してみます。
#include <iostream>
using namespace std;
int main()
{
int hanako_age = 15; //hanako_ageを定義
int &yamada_age = hanako_age; //hanako_ageの別名としてyamada_ageを定義
cout << "hanako_age_add = " << &hanako_age << endl; //hanako_ageのアドレスを確認
cout << "yamada_age_add = " << &yamada_age << endl; //yamada_ageのアドレスを確認
hanako_age = 20; //A : hanako_ageを20に変更
cout << "hanako_age = " << hanako_age << endl;
cout << "yamada_age = " << yamada_age << endl;
yamada_age = 18; //B : yamada_ageを20に変更
cout << "hanako_age = " << hanako_age << endl;
cout << "yamada_age = " << yamada_age << endl;
return 0;
}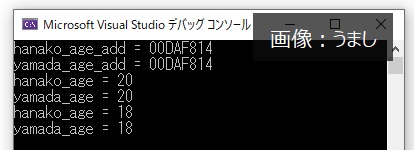
hanako_ageとyamada_ageは同じ変数(アドレスも同じ)なので
・hanako_age_addとyamada_age_addは同じアドレス
・Aでhanako_ageを変更するとyamada_ageも変更される
・Bでyamada_ageを変更するとhanako_ageも変更される
この動きは理解しやすいかと思います。ではちょっと実験してみます。『&』を外すとどうなるでしょうか?
#include <iostream>
using namespace std;
int main()
{
int hanako_age = 15; //hanako_ageを定義
int yamada_age = hanako_age; //&を外してyamada_ageを定義
cout << "hanako_age_add = " << &hanako_age << endl; //hanako_ageのアドレスを確認
cout << "yamada_age_add = " << &yamada_age << endl; //yamada_ageのアドレスを確認
hanako_age = 20; //A : hanako_ageを20に変更
cout << "hanako_age = " << hanako_age << endl;
cout << "yamada_age = " << yamada_age << endl;
yamada_age = 18; //B : yamada_ageを20に変更
cout << "hanako_age = " << hanako_age << endl;
cout << "yamada_age = " << yamada_age << endl;
return 0;
}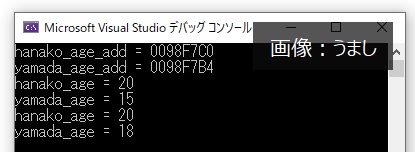
&を外すと、hanako_ageとyamada_ageは別の変数として宣言したことになります。そのため、アドレスも違いますし、AやBで値を変更しても、相手は影響を受けていないことが分かります。
もう1つ実験をしてみます。C言語でおなじみのポインタを使用して参照のような動きをしてみます。
#include <iostream>
using namespace std;
int main()
{
int hanako_age = 15; //hanako_ageを定義
int *yamada_age_add; //yamada_age_addはポインタで宣言
yamada_age_add = &hanako_age; //yamada_age_addにhanako_ageのアドレスを代入
cout << "hanako_age_add = " << &hanako_age << endl; //hanako_ageのアドレスを確認
cout << "yamada_age_add = " << yamada_age_add << endl; //yamada_ageのアドレスを確認
hanako_age = 20; //A : hanako_ageを20に変更
cout << "hanako_age = " << hanako_age << endl;
cout << "yamada_age = " << *yamada_age_add << endl;
*yamada_age_add = 18; //B : yamada_ageを20に変更
cout << "hanako_age = " << hanako_age << endl;
cout << "yamada_age = " << *yamada_age_add << endl;
return 0;
}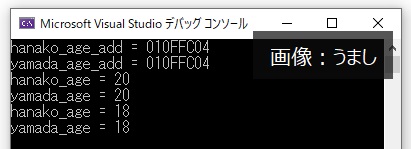
ポインタを使用すると最初に確認した参照のような動きになっていることが分かります。C言語に慣れ親しんでいる方には「何をいまさら」と感じるかもしれませんが、ポインタに慣れていない方は「なんだ?意味が分からない」と感じたかもしれません。
これは、次の項の値渡し、ポインタ渡し、参照渡しにつながる重要な考え方になります。
値渡し・ポインタ渡し・参照渡しの違い
C++では、関数に引数を渡す方法に
①値渡し
②ポインタ渡し(アドレス渡し)
③参照渡し
この3つの方法があります。値渡しはその名の通り変数の値のみを渡す方法、ポインタ渡しは関数にアドレスを渡す方法、参照渡しは参照の機能を利用して元の変数にアクセスする方法です。
説明だけでは分かりにくいかと思いますので、簡単な関数を実行しながらそれぞれの動作を確認してみます。
#include <iostream>
using namespace std;
void PrintAge(int age) //値渡しで引数を渡す関数
{
age = 20;
cout << age << endl;
}
void PrintAgeAdd(int *age) //ポインタ渡しで引数を渡す関数
{
*age = 25;
cout << *age << endl;
}
void PrintAgeRef(int &age) //参照渡しで引数を渡す関数
{
age = 18;
cout << age << endl;
}
int main()
{
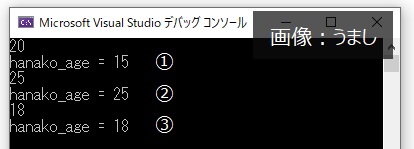
int hanako_age = 15; //hanako_ageを宣言。初期値は15を代入
PrintAge(hanako_age);
cout << "hanako_age = " << hanako_age << endl; //値渡し後のhanako_ageの値を表示
PrintAgeAdd(&hanako_age);
cout << "hanako_age = " << hanako_age << endl; //ポインタ渡し後のhanako_ageの値を表示
PrintAgeRef(hanako_age);
cout << "hanako_age = " << hanako_age << endl; //参照渡し後のhanako_ageの値を表示
return 0;
}
それぞれの動作の違いを理解してもらえたでしょうか?
①の値渡しでは値はもらいますが、元の『hanako_age』には影響を与えません。しかし、②ポインタ渡し、③参照渡しでは元の『hanako_age』の値を書き換えていることが分かります。このように引数の渡し方で元の変数自体も書き換えたり、書き換えなかったりと動きが変わります。
余談ですが、Pythonというプログラミング言語は全て参照渡しという特徴があるので、値渡し?ポインタ渡し?のように悩むことがありません。
vector
配列はたくさんのデータを保持することができて便利ですが、C++では『vector』という便利なオブジェクトを利用することもできます。配列はa[6]のように最初に要素の数を指定する必要がありますが、vectorは要素を後から追加・削除することができるという特徴があり動的にメモリを確保して使用することができます。実際に使用してみます。
#include <iostream>
#include <vector> //インクルードが必要
using namespace std;
int main()
{
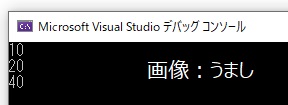
vector <int> num; // int型を入れるvectorオブジェクトを生成
num.push_back(10); // num.push_back[a]でaの値を追加する
num.push_back(20);
num.push_back(30);
num.pop_back(); // num.pop_back(); で最後の要素を削除
num.push_back(40);
cout << num[0] << endl; // 10 まずは見やすいようにfor文は使用していません
cout << num[1] << endl; // 20
cout << num[2] << endl; // 40
}
次はfor文を利用してvectorオブジェクトを出力してみます。難しそうに見えますが書き方がちょっと長いだけでただのfor文です。
for (i = 0; i < 要素数; ++i) //配列
// 先頭がちょっと長いだけ
for (vector<string>::size_type i = 0; i < str.size(); ++i) //vector実際にコードで確認してみます。今度は文字列クラス(stringクラス)です。
#include <iostream>
#include <string>
#include <vector>
using namespace std;
int main()
{
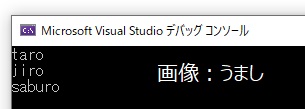
vector<string>str;
str.push_back("taro");
str.push_back("jiro");
str.push_back("saburo");
for (vector<string>::size_type i = 0; i < str.size(); ++i) {
cout << str[i] << endl;
}
}
vectorとイテレータ(反復子)
前回の項で『vector』をご紹介しましたが、vectorはiterator(イテレータ)と合わせて使用されることが多いです。iteretorは反復子とも呼ばれます。使い方だけご紹介します。
#include <iostream>
#include <string>
#include <vector>
using namespace std;
int main()
{
vector<string>str;
str.push_back("taro");
str.push_back("jiro");
str.push_back("saburo");
vector<string>::iterator itr_start, itr_end, itr;
itr_start = str.begin(); //先頭の要素をiteratorに代入
itr_end = str.end(); //最後の要素をiteratorに代入
for (itr = itr_start; itr != itr_end; itr++) {
cout << *itr << endl;
}
}